1. DOM 개념 이해하기
1-1. DOM(Document Object Model) 이란?
1) DOM은 문서 객체 모델의 약어로 HTML과 XML 문서를 위한 API(Application Programmi
ng Interface)로서 문서의 물리적 구조와 문서가 접근되고 다루어지는 방법을 정의한다.
2) DOM의 목적
(1) 다양한 환경과 애플리케이션에서 사용할 수 있는 표준적인 프로그래밍 인터페이스 제공
(2) 프로그램 또는 스크립트를 통해 HTML이나 XML같은 웹 문서의 내용과 구조 그리고
스타일 정보의 검색 또는 수정이 가능하도록 해주는 플랫폼 또는 언어에 중립적인 인터
페이스이다.
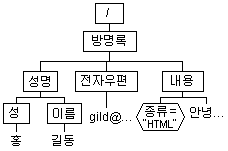
3) DOM 문서를 이용한 XML 문서 생성 과정
(1) XML 문서를 취급하기 위하여 프로그램에서 XML 문서를 읽어들인다.
(2) XML 문서를 XML 파서에 의해 트리 구조로 만든다.
(3) DOM API를 이용하여 읽어들인 XML 문서에 대한 엘리먼트, 텍스트, 애트리뷰트 내용
을 추출한 후 XML 문서를 조작(추가,삭제,갱신) 한다.
(4) 조작되어진 XML 문서를 프로그램이 마무리하여 생성 혹은 갱신하게 된다.
1-2. DOM Level
1) DOM 스펙은 W3C에서 Level 단위로 만들어지고 있는데, 처음에 만든 권고안 DOM Lev
el 1 이었고, 현재는 DOM Level 3 권고안까지 만들어진 상태이다.
2) DOM 레벨에 관한 정보
⊙ DOM Level 1 : core, HTML, 그리고 XML 문서모델에 대한 내용이다. 레벨1은 문서
에 대하여 항해(navigation)하거나 조작(manipulation)하는 기능을
포함한다.
⊙ DOM Level 2 : 스타일 쉬트를 적용한 개체모델을 지원하고 문서에 스타일 정보를
조작하는 기능을 정의한다. 또한 문서에 대한 풍부한 질의 기능과
이벤트 모델에 대한 정의 기능도 포함한다.
⊙ DOM Level 3 : 윈도우즈 환경 하에서 사용가능한 사용자 인터페이스를 기술하는
것까지 포함한다. 이를 이용하여 사용자는 문서의 DTD를 조작하는
기능과 보안 레벨까지 정의할 수 있다.
1-3. DOM 기반 Parser
1) DOM 기반 파서는 DOM API 라는 프로그램 라이브러리를 사용한다. 이 라이브러리를
이용하면 XML 문서의 테이터를 엑세스하고 변경하기 위해 DOM 트리에 있는 노드를
다룰 수 있다. 여러 언어로 작성되어 있으며 보통 무료로 다운 받을 수 있다. 여러 응용
프로그램-인터넷 익스플로러 6(msxml 3.0 기본 내장) 에서 파서를 이미 내장하고 있다.
2) 대표적인 DOM 기반 파서 (지원버전 : DOM Level 2 SAX 2.0)
⊙ JAXP : 썬 마이크로시스템의 파서(Java API for XML Parsing)
http://java.sun.com/xml
⊙ XML4J : IBM의 파서(XML Parser for Java)
http://www.alphaworks.ibm.com/tech/xml4j
⊙ Xerces : 아파치의 파서(Xerces Java Parser) http://xml.apache.org/
⊙ msxml : 마이크로소프트 파서 http://msdm.microsoft.com/xml
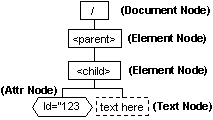
1-4. DOM 구조와 원리
DOM은 XML 문서에 노드 클래스의 하위 클래스 인스턴스로 표현되는 노드들의 트리로
표현되는데, 특정 노드의 하위클래스는 요소, 텍스트, 주석이 될 수 있다. 따라서 DOM은
트리 구조로서 XML 문서를 다루게 되는 것이다.
1) DOM을 이용한 XML 문서변환
XML 문서를 응용프로그램이 파싱 요청을 하면 XML 파서에 의해 해석한 후 DOM 인터
페이스를 이용하여 응용프로그램과 정보를 서로 전달하여 XML문서를 조작하도록 하고
있다.
2) XML 문서와 DOM 트리구조
(1) XML 문서
<?xml version="1.0" encoding="euc-kr" ?>
<책>
<제목>XML 정목</제목>
<발행년도>2004년 발행</발행년도>
</책>
(2) DOM 노드 트리 모델링
[ Document ]
(NodeList)
[Element "책"]
(NodeList)
(NodeList) (NodeList)
[Element "제목"] [Element "발행년도"]
[NamedNodeMap "분류"] [NamedNodeMap "분류"]
[Att Node "컴퓨터"] [Att Node "발행"]
(NodeList) (NodeList)
[Text CharacterData "XML 정복"] [Text CharacterData "2004년 발행"]
3) XML 문서에서의 객체
(1) XML 문서
<?xml version="1.0" encoding="euc-kr" ?>
<책>
<제목 분류="컴퓨터">XML 정복</제목>
<발행년도 분류="발행">2004년 발행</발행년도>
</책>
(2) XML 객체
⊙ Documents : 작성된 전체 문서를 대표하는 객체이다.
⊙ <책> : 2개의 하위 요소 객체인 <제목>과 <발행년도>를 포함한 루트 객체이다.
⊙ <제목> : 다음 요소객체로 <발행년도>를 갖고 "XML 정복"라는 text객체를 소유함.
⊙ XML 정복 : <제목> 객체의 text객체가 된다.
⊙ <발행년도> : 이전 요소객체로 <제목>를 갖고 "2004년 발행"이라는 text객체를 소유
한다.
⊙ 2004년 발행 : <발행년도> 객체의 text객체가 된다.
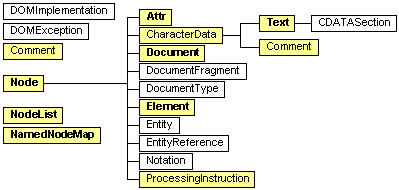
2. DOM API
2-1. DOM 인터페이스
1) W3C에 의해 추천된 프로그래밍 규격으로, 프로그래머가 HTMl 페이지나 XML 문서들을
프로그램 객체로 만들거나 수정할 수 있도록 해주며, 그저 데이터 구조의 형태로 문서를
표현하고 있는 현재의 HTML과 XML 문서들을 DOM 인터페이스를 사용하여 마치 프로
그램 객체처럼, 자신들의 컨텐츠나, 객체 내에 감추어진 데이터를 가질 수 있게 됨으로써,
문서를 조작할 수 있게 된다.
⊙ Document
⊙ Node
⊙ Nodelist
⊙ Element
⊙ NamedNodeMap
2-2. Document 인터페이스
Document 인터페이스는 HTML 또는 XML 문서를 나타내기 위해 사용하는데 문서 트리
구조에서 최상위 루트에 해당한다.
1) Document 인터페이스의 특징
(1) 엘리먼트, 텍스트노드, 주석(comments), 처리 명령(processing instructions) 등을
포함하지 않고는 Document 인터페이스가 존재할 수 없다.
(2) Document 인터페이스는 이 객체들을 만드는데 필요한 메소드 요소들도 포함하며
생성된 Node 객체들은 Document와 Node를 관련짓는 속성을 가진다.
(3) Document 인터페이스
⊙ Element getDocumentElement()
⊙ NodeList getElementsBytagName(String tagname)
⊙ Element createElement(String tagName)
⊙ Text createTextNode(String data)
⊙ Attr createAttribute(String name)
2) Document 인터페이스의 메소드
(1) Element getDocumentElement()
XML 문서에서 루트요소를 얻기 위해 메소드로 처음 XML 트리 구조를 접할 때 가장
먼저 루트요소를 접근한 후에 세부적으로 접근하게 된다.
(2) NodeList getElementsBytagName(String tagname)
XML 문서에서 요소리스트를 얻기 위해 사용되는 메소드인데 인자 값은 tagName이
올 수 있는데 tagName 이후의 모든 요소리스트를 반환하게 된다.
(3) Element createElement(String tagName)
지정된 형식의 ELEMENT를 생성하는 메소드이다. 이 메소드는 인자 값으로
tagName을 사용할 수 있는데 XML에서 설명한 엘리먼트 형식 이름이다.
(4) Text createTextNode(String data)
지정된 문자열을 가진 Text 노드를 생성하는 메소드로 인자 값으로 그 노드에 대한
데이터를 가지며 리턴 되는 값은 새로운 Text 객체이다.
(5) Attr createAttribute(String name)
주어진 이름의 Attribute를 생성하는데 인자 값은 속성의 이름인 name이다. 또한 반환
값은 새로운 Attr객체로써 만약 이름이 적당하지 않은 문자를 포함하면 에러를 발생함.
3) Node 인터페이스
Node 인터페이스는 XML 문서에서 노드 트리의 각 요소를 읽고 쓰기 위해 사용되는데
DOM에서 가장 기본적인 자료형으로 쓰인다.
(1) Node 인터페이스의 특징
Node 인터페이스는 원소, 주석, 속성들을 상속받으며 이중에 최하위 노드인 Text
노드는 자식을 가질 수 없다. 만약 Text노드에 자식을 추가하면 DOMException 에러
가 발생하게 된다.
▣ 노드에 관한 정보(NodeType)
|
구분 |
노드종류 |
노드명 |
노드값 |
|
Element |
ELEMENT_NODE |
요소명 |
null |
|
Attribute |
ATTRIBUTE_NODE |
속성명 |
속성값 |
|
Text |
TEXT_NODE |
#text |
노드의 내용 |
|
CDATA |
CDATA_SECTION_NODE |
#cdata-section |
노드의 내용 |
|
Entity |
ENTITY_NODE |
참조된 엔티티 이름 |
null |
|
Entity
Reference |
ENTITY_REFERENCE_NODE |
선언된 엔티티 이름 |
null |
|
Processing Instruction |
PROCESSING_INSTRUCTION_NODE |
PI이름 |
PI이름을 제외한 전체 내용 |
|
comment |
COMMENT_NODE |
#comment |
주석 내용 |
|
Document |
DOCUMENT_NODE |
#document |
null |
|
Document Type |
DOCUMENT_TYPE_NODE |
루트요소명 |
null |
|
Notation |
NOTATION_NODE |
Notaion선언이름 |
null |
|
DOCUMENT
FRAGMENT |
DOCUMENT_FRAGMENT |
#document-fragment |
null |
(2) Node 인터페이스의 메소드
▣ Node getFirstChild() : 현재 노드의 첫 번째 노드를 나타내고 만약 그런 노드가
없으면 null값을 반환하며 리턴값은 node이다.
▣ Node getNextSibling() : 현재 노드의 바로 다음 노드를 나타낼 때 사용되는 메소
드로서 만약 해당 노드가 없으면 null값을 반환하고, 리턴값은 node이다.
▣ short getNodeType() : 노드의 종류를 나타내는 메소드로 반환되는 값은 정수형
값을 가진다.
< 노드의 종류와 상수 값 >
|
멤버필드 이름 |
정수값 |
노드 종류 |
|
Node.ELEMENT_NODE |
1 |
Element |
|
Node.ATTRIBUTE_NODE |
2 |
Attr |
|
Node.TEXT_NODE |
3 |
Text |
|
Node.CDATA_SECTION_NODE |
4 |
CDATASection |
|
Node.ENTITY_REFERENCE_NODE |
5 |
EntityReference |
|
Node.ENTITY_NODE |
6 |
Entity |
|
Node.PROCESSING_INSTRUCTION_NODE |
7 |
ProcessingInstruction |
|
Node.COMMENT_NODE |
8 |
Comment |
|
Node.DOCUMENT_NODE |
9 |
Document |
|
Node.DOCUMENT_TYPE_NODE |
10 |
DocumentType |
|
Node.DOCUMENT_FRAGMENT_NODE |
11 |
DocumentFragment |
|
Node.NOTATION_NODE |
12 |
Notation |
▣ string getNodeName() : 노드의 이름을 나타내는 메소드로 해당 노드의 이름을 문자열 형으로 반환한다.
▣ string getNodeValue() : 노드의 값을 나타내는 메소드로 문자열형으로 해당 노드의 값을 반환한다.
▣ Document getOwnerDocument() : 현재 노드와 연결된 Document 객체를 나타내는 메소드로 새로운 노드를 만드는 데 사용되는 Document 객체이기도 하다. 이 노드가 Document이면 null값을 반환한다.
▣ Node appendChild(Node newChild) : appendChild 메소드는 새로운 노드를 추가할 때 사용하는데, newChild 노드를 현재 노드의 자식 리스트의 끝에 삽입한다. newChild가 DocumentFragment객체이면 DocumentFragment의 전체 내용이 현재 노드의 자식 리스트 안으로 삽입된다.
▣ Node getParentNode() : getParentNode 메소드는 현재 노드의 부모 노드를 나타
내는 메소드로 All nodes, except Document, DocumentFragment, 그리고 Attribute
를 제외한 모든 노드가 부모를 가질 수 있다. 그러나 노드가 만들어졌지만 트리에 추가되지 않았거나 트리에서 제거되지 않았을 경우 이것은 null 값을 반환한다.
▣ Node insertBefore(Node newChild, Node refChild) : insertBefore 메소드는 원하는 특정 위치(refChild)에 새로운 노드(newChild)를 삽입할 때 사용하느데, 이때 삽입되는 위치는 refChild의 이전 위치가 된다. 만약 refChild가 null값이면 자식 리스트의 끝에 newChild를 삽입하고, newChild가 DocumentFragment 객체이면refChild 앞에 같은 순서로 모든 자식들이 삽입된다. 만약 newChild가 이미 트리안에 있으면 먼저 제거된 후에 삽입된다.
▣ Node replaceChild(Node newChild, Node refChild) : replaceChild 메소드는새 노드를 나타내는 newChild와 리스트에서 대체되는 노드를 나타내는 refChild를 가지며, 노드 refChild를 newChild로 대체한다. newChild가 이미 트리상에 존재하지만 먼저 제거한 후에 삽입된다.
▣ Node removeChild(Node oldChild) : removeChild 메소드는 인자 값으로 제거될노드 oldChild를 가지며, 자식 리스트로부터 oldChild에 해당하는 노드를 제거한다. 만약 현재 노드가 읽기 전용일 때에는 NO_MODIFICATION_ALLOWED_ERR 에러를 발생시킨다.
▣ NamedNodeMap getAttributes() : 노드의 속성리스트를 얻는다.
4) NodeList 인터페이스
NodeList 인터페이스는 노드들의 집합이 구현되는 방법을 정의하거나 순서가 있는 노드
들의 집합을 표현할 때 사용한다.
(1) NodeList 인터페이스의 특징
NodeList에서의 아이템은 0부터 시작되는 정수 인덱스에 의하여 접근할 수 있으며
NodeList를 통해 얻은 노드들의 순서는 XML에서 부모노드로부터 추가한 순서가
된다.
(2) NodeList 인터페이스의 메소드
▣ int getLength() : 노드의 개수를 나타내는데 자식 노드 인덱스 범위은 0에서
length-1까지이다.
▣ Node item(int index) : 노드리스트 안에서 노드의 인덱스 값을 인자로 가지며,
노드리스트에서 index가 가리키는 노드를 반환한다. 또한 index가 리스트에서의
노드 개수보다 많거나 같을 때에는 null값을 반환한다.
5) Element 인터페이스
Element 인터페이스는 HTML 문서 또는 XML 문서의 원소를 표현하기 위해 사용된다.
(1) Element 인터페이스의 특징
Attribute 객체 또는 속성값 등을 검색할 수 있는 메소드를 가지고 있다. 그리고 모든속성이 간단한 문자열 값을 가지는 HTML에서 속성값에 직접 접근할 수 있는 방법들이 사용될 수 있다.
(2) Element 인터페이스의 메소드
▣ getAttribute(String name) : 검색할 속성이름인 name을 인자로 갖는다. 이때 반환되는 값은 문자열인 Attr 값, 또는 그 속성이 지정된 값을 갖는데 만약, 기본 값이없을 경우 빈 문자열이 된다.
▣ setAttribute(String name, String value) : 주어진 이름과 값을 갖는 속성을 추가하 는데 동일한 이름을 가진 속성이 존재할 경우 값을 변경한다.
▣ removeAttribute(String name) : 주어진 이름(name)의 속성을 제거하는 메소드인 데 현재 노드가 읽기 전용일 때 NO_MODIFICATION_ALLOWD_ERR 에러를 발생시키며 반환 값은 없다.
6) NameNodeMap 인터페이스
NameNodeMap 인터페이스는 NodeList의 기능과 유사한데 이름을 이용하여 노드에 접근하고 NameNodeMap을 구현하는 객체에 포함된 속성들을 추출할 때 사용한다.
(1) NameNodeMap 인터페이스의 특징
접근하려는 노드들은 이름과 0부터 시작하는 정수 인덱스 값을 이용해 추출할 수 있다.
(2) NameNodeMap 인터페이스의 메소드
▣ Node getNamedItem(String name) : 이름을 이용하여 지정된 노드를 검색하고, 검색할 노드의 이름을 인자로 갖는다. 반환되는 값은 지정된 이름을 가진 노드이며지정된 이름이 맵에서 어떤 노드도 일치 않으면 null 값을 반환한다.
▣ Node removeNamedItem(String name) : 제거될 노드의 이름을 이자로 가지며 이름에 의해 지정된 노드를 제거한다. 만약 동일한 이름의 노드가 없다면 null값을반환한다. 그리고 맵 전체에 지정한 이름의 노드가 없을 때 NOT_FOUND_ERR 에러를 발생시킨다.
▣ Node item(int index) : 정수를 인자로 가지며 index에 해당하는 Attr 노드 객체를 리턴하고, index에 해당하는 특성이 존재하지 않으면 null값을 리턴한다.